
○ 이어가는 글
https://kuck-su-labor.tistory.com/62
위 글에서 이어집니다.
○ 들어가는 글
우리는 Knapsack Problem을 해결하기 위해서 다음과 같은 순서로 알고리즘을 구성할 수 있다고 했습니다.
| 1. 기본적으로 알고리즘은 재귀를 이용한 완전 탐색을 사용합니다. |
| 2. 이를 통해서 한 번의 노드 탐색이 끝나고, 최대로 담을 수 있는 V값을(한 번의 순회로 얻어진) 구합니다. |
| 3. 다음 순회를 진행할지 결정하는 지표 FV를 구합니다. 이는 가성비대로 선택, 남는 공간은 분할하여 최대로 담아 얻어진, 순회로 얻을 수 있는 최대의 예상 값입니다. |
| 4. V와 FV를 비교하여 만약 FV가 V의 값보다 작다면 ( FV < V ) 앞으로의 순회에서 FV보다 큰 값이 나올 확률이 없으므로 순회를 종료하고 V를 해로 선정합니다. |
| 5. V와 FV를 비교하여 만약 FV가 V의 값보다 크다면 ( FV > V ) 앞으로의 순회에서 기존의 V보다 더 큰 값이 나올 수 있으므로 순회를 계속합니다. (2번으로 돌아갑니다.) |
이렇게 글로만 적어놓고 보면 한눈에 어떻게 알고리즘이 작동하는지 알기 쉽지 않습니다. 따라서 우리는 구현하기 전에, 실제로 알고리즘이 어떻게 동작하는지 세세히 다루면서 따라가 보도록 하겠습니다.
○ 1. 정렬
greedy 알고리즘을 사용하기 위해서 우선은 정렬을 수행합니다. 추후에 계속 순회를 속행할지 판단하는 최댓값을 구하기 위해서 정렬을 수행합니다. 정렬기준은 가성비로 가치를 무게(또는 크기)로 나눈 값이 큰 순서대로 정렬합니다. 결과는 다음과 같습니다.

○ 2. 완전 탐색 트리 구현
우리는 기본적으로 완전 탐색으로 해를 구합니다. 이 과정에 있어서는 우리가 한번 다뤄본 적이 있습니다. 아래 글과 크게 다른 것은 없지만, 우리는 요소값을 정렬하였기 때문에, 그림을 다시 그려보겠습니다.
이전글 : https://kuck-su-labor.tistory.com/61

짜잔
우선 우리가 완전 탐색으로Knapsack Problem을 풀기 위한 완전 탐색 트리를 구성하였습니다.
○ 3. 노드 순회
여기서 우리는 노드를 순회해 가면서, 여러 가지 경우의 수를 만들 것입니다. 기본적으로 전위 순회이기 때문에 기본적으로 다음 방향으로 순회합니다. 그렇다면 다음 노드는 왼쪽 노드부터 순회하게 될 것입니다.

○ 4. 가치의 최댓값 구하기
만약 노드에 도착을 했다면 우선 먼저 가치의 최댓값을 구합니다. 우리는 구할 수 있는 경우의 수 중에 가치가 가장 높은 것을 구합니다. 이는 가치의 대한 최댓값을 설정하고 이전 최댓값과 노드의 있는 값을 비교하면서, 만약 노드의 값이 더 크다면 최댓값을 노드의 값으로 재설정하고, 아니라면 아무것도 하지 않습니다.
우리는 기본적으로 최댓값은 0으로 설정할 것이며, 루트 노드의 값 또한 0이었기 때문에, 자동적으로 최댓값은 다음 노드의 것으로 바뀌게 됩니다.

○ 5. 다음 노드의 예상 최댓값 구하기 1
이전글 : https://kuck-su-labor.tistory.com/62
이전 글에서 다루었듯이 우리는 굳이 모든 순회, 즉 모든 경우의 수를 구할 필요가 없다고 말씀드렸습니다. 만약 앞으로 나올 수 있는 값의 예상 최댓값을 구할 수 있고, 이가 지금까지 구한 최댓값보다 작다면 굳이 순회를 진행하지 않고, 지금의 최댓값으로 해를 만들 수 있다고 말입니다. 지금까지 우리는 구한 최댓값을 알고 있기 때문에, 앞으로의 예상 최댓값만을 알아내면 됩니다.
우선, 아래의 그림을 보면 노드를 순회한다고 가정하면 3 부분으로 나뉠 수 있다는 것을 알 수 있습니다.

1. 지금까지 순회를 진행한 부분
2. 순회를 진행할 부분
3. 나머지
우선 1번은 우리 지금까지 구한 부분이며, 3번은 아직 우리가 순회를 진행할 부분은 아닙니다. 우리는 나머지 부분(2번)에서 구할 수 있는 최댓값을 구하고자 하는 것입니다.
우리는 2번 영역의 구성 요소들 ( 첫 번째 노드를 순회했다는 것은 첫 번째 요소인 가치가 {5}인 것을 이미 선택했다는 의미 이므로 이를 제외한 나머지 구성요소 {3,4,5} ) 로 Greedy 알고리즘을 수행해서 예상 최댓값을 구할 수 있을 것입니다.

○ 6. 다음 노드의 예상 최댓값 구하기 2
예상 최댓값을 구하기 전에 이는 이미 정렬이 전제되어야 있어야 합니다. 1번 단계에서 정렬을 수행한 이유입니다.
이제 나머지 구성 요소들로 예상 최댓값을 구해봅시다. 지금 공간에 지금 7의 공간에서 3 값이 들어가 있는 상태이기 때문에 남은 4의 공간에 요소를 담을 수 있을 것입니다. 우리는 최대한 넣을 수 있는 만큼 넣어봅니다. 크기 2를 가진 요소를 넣으면, 7의 크기 중에서 2의 크기가 남지만 다음 넣은 것은 3의 값입니다. 넣을 수 있는 공간이 부족하기 때문에 더 이상 넣을 수 없습니다.

하지만 지금은 공간이 남는다면, 더 넣어서 모든 공간에 할당해야 합니다. 우리는 다음에 넣을 요 소을 무게(크기)의 값으로 나눈 가성비를 남은 공간만큼 넣어서 공간을 모두 할당한 최댓값을 구할 수 있습니다.

가치 4 , 크기크기 3의 요소는 크기 1당 1.3의 가치를 가지고 있습니다. 따라서 총 2.6의 가치를 더 가져갈 수 있습니다. 결과적으로 우리가 예상할 수 있는 최대 가치는 10.6입니다.
○ 7. 지금의 가치와 예상 값과의 비교
지금까지 우리가 구한 가치의 최댓값은 5이며, 예상 가치 최댓값은 10.6입니다. 즉 앞으로의 순회과정에서 10.6 이상의 값은 나오지 않는다는 이야기 입니다. 하지만 반대로 말하면 10.6 이하는 값이 나올수도 있다는 뜻입니다. 지금까지 구한 가치의 최댓값은 5이고 이는 10.6보다 적기 때문에 순회를 종료하면 안 되며, 계속 순회를 진행해야 합니다. 이러한 과정을 모든 노드를 순회할 때마다 진행하면 됩니다.
○ 8. 순회를 종료하는 경우
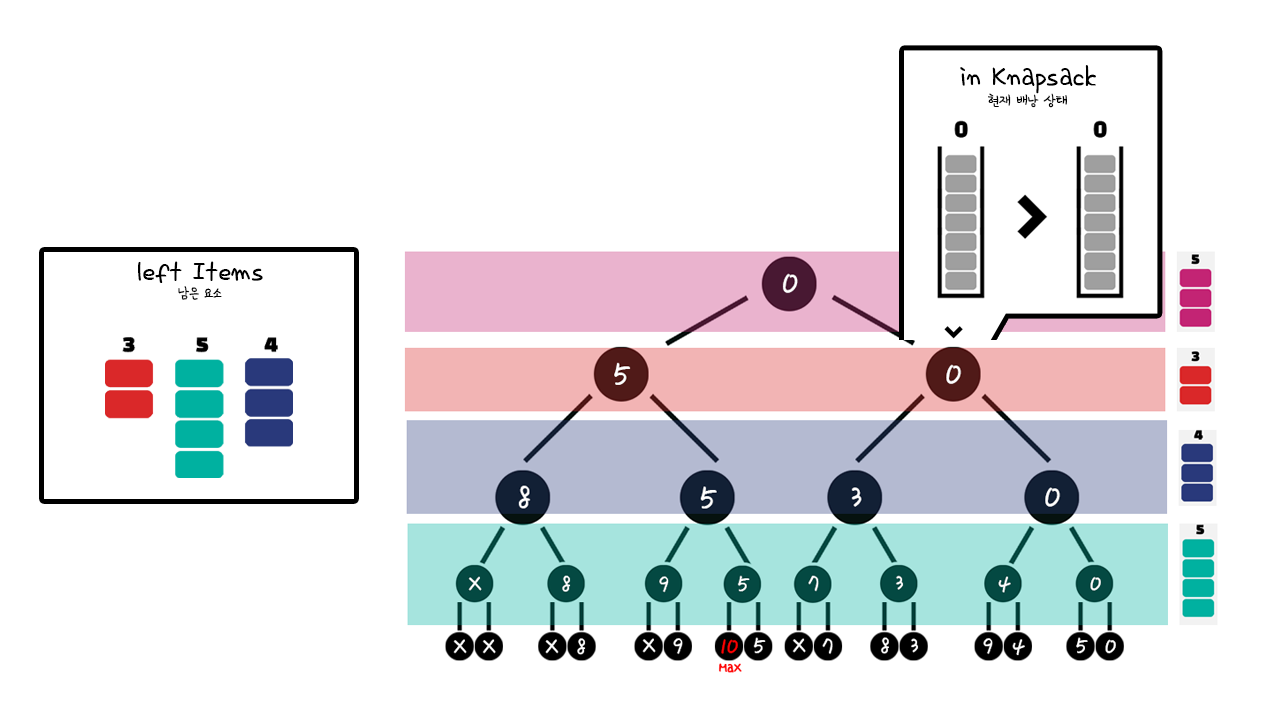
순회를 종료하는 경우의 대해서 알아보겠습니다. 다음의 순회까지 진행했다고 가정합니다. 지금의 상황에서 가치의 최댓값은 10입니다. 이 상황에서 우리는 가치가 5인 요소를 선택하지 않은 상태이며, 나머지 가치가 {3,4,5}인 요소만을 가지고 예상 최댓값을 만들어 비교할 수 있을 것입니다.

예상 최댓값을 만들어보면 다음과 같습니다. 따라서 우리는 9.5라는 예상 가치 최댓값을 얻을 수 있습니다. 즉 이 노드의 자식 노드에서는 적어도 9.5 이상의 값은 얻을 수 없습니다. 하지만 지금까지 얻은 최대가치는 10이기 때문에 앞으로의 순회는 무의미합니다. 따라서 여기서 순회를 종료해도 무방합니다.
○ [참고]. 순회를 하게 되는 영역
지금의 예시로 따진다면, 실제로 순회하게 되는 영역은 다음과 같습니다. 상당히 순회를 줄일 수 있다는 것을 알 수 있습니다.

다음글에서 이어집니다...
( 다음 글에서는 실제로 구현하는 것을 목표로 하겠습니다. )
ps)
참고 :
'알고리즘 5+1' 카테고리의 다른 글
| Kotlin diary (1) - 자주 사용했던 것들 (0) | 2021.05.30 |
|---|---|
| Knapsack Problem(4) - 알고리즘 구현하기 (0) | 2021.05.22 |
| Knapsack Problem(2) - 근사 알고리즘 적용하기 (0) | 2021.05.10 |
| Knapsack Problem(1) - (재귀로 구현하기) (0) | 2021.04.30 |
| 탐욕 알고리즘(2) - (greedy 알고리즘 활용 - 강의실 배정문제 ) (0) | 2021.04.21 |